A Novel Object Oriented Video Search Engine
Shilin Xu
Overview
Our mission is providing a search interface to users so they can easily locate a specific object within the videos over the internet. In order to achieve that, we need to understand the video over the internet first. We implement a video understanding system, running in the background, crawling videos from the internet, and populating the observation results, then the search engine queries from the observation results, ranks the results, finally presents the video list to the users.
This document serves as a technical entry point to our system design and implementation. We would like to give the audience a very high-level description but won’t dive too deep into the technical details. We hope the audience to use this document either as a technical glance to the system, or as a side user manual to understand our system better and use it better.
Video Understanding System
Digital videos over the internet are mostly stored with various compression formats in different media containers. For example, mp4 is a type of media container. Within mp4, there are video tracks, audio tracks and metadata tracks. The raw video data is normally compressed into bit stream conformant with industry standards such as H.264, H.265 or VP9. The video data is purely a binary file which is completely unstructured and looks like random data if you don’t have a decoder. Even though the video is decoded to uncompressed format such as YUV or RGB, the computer still has no idea what content the video is presenting. Thanks to the most recent achievements from the artificial intelligence, we have various AI models so that the computer is able to recognize the objects within an image, and this is our start point.
We feed video into the AI models then obtain a list of objects that the AI model recognizes. We develop technologies to further extract their visual features, analyze their temporal and spatial presence, and finally generate a document-based description for this video. By doing so, we convert the unstructured binary video data into a fully structured, searchable and understandable document which can be easily processed by computers. These documents present the video to computer in the mimic manner as humans observe, memorize and understand the video. Consequently, our system provides a computer interface to human users so they can ask the computer to process the video in the similar way as a human understands it.
We also implement a video crawling system, which finds videos from the internet and then feeds them to the video understanding system. There is no human interference involved and the crawler picks up the video pretty randomly from the main stream video distribution websites. We never store or stream the video, but just generate the description documents for the video our computers have watched thus the user could conveniently search for it. Our search engine only points to the user the URLs of the target videos, but never owns the video, much likely the same way as all other main stream search engines do.
What Objects Can Be Recognized?
Video understanding system generates object labels, describes object visual features, populates the video metadata, and manages the video documentation system. Some essential questions emerge here, what objects can the video understanding system recognize? What words does the video understanding system use to label the recognized objects? For users, is there any restrictions regarding the objects being queried?
To answer all the above questions, let’s firstly introduce WordNet [1]. WordNet is a lexical database of English. It groups nouns, verbs, adjectives and adverbs into sets of cognitive synonyms (synsets), each expressing a distinct concept. Our search engine for now only focuses on the nouns part. Each synset, in the nouns part, represents a distinct object or a group of objects with similar features. For example, if a truck appears in a particular video, the video understanding system will recognize it and label it as the object type “truck”. When a user queries for “truck”, the search engine will translate the word “truck” into its corresponding synset in WordNet then send the query to the video understanding system, finally the above video fragment where the truck appears will be populated into the search result.
There are roughly 82,000 nouns synsets in WordNet. Among them we currently support ~3500 synsets, which is still a small piece of the entire set but it’s just the beginning! If you look around your house, you may find that the number of distinct types of objects is large. Think about how many types of distinct objects exist around the world? The number may be countless. In order to provide a practical search tool, we start with a very small number of objects (synsets in WordNet) which humans are most familiar with. These 3500 synsets are our start point, and we believe it opens a door to a brand new magic world! For the entire list of these 3500 objects, please refer to “supported objects” page.
How does the Search Engine Handle the Input from User?
The search engine only accepts text as input for now. When the user submits the query string, the search engine in the background will convert the string into the synset of WordNet. The synset of WordNet is the “common language” being used throughout the entire system. The search engine tries its best to understand the user’s input word(s), translates them into synset(s) or pops out errors if it has troubles to understand or the user’s input is not supported yet.
How to Phrase the Query to Search Engine?
Our search engine allows the user to input any word(s) in the search text box so another question arises: what words are acceptable by the search engine? Is there any rule and what will happen if I input erroneous word(s) or words not supported yet?
Let’s still use the above example “truck”. If the user inputs “2010 Ford F-150 pickup truck”, what will happen? The search engine gets string “2010 Ford F-150 pickup truck”, then it tries to find its correspondent synset from WordNet. But unfortunately, “2010 Ford F-150 pickup truck” is not a synset of WordNet, thus this input is not supported. How about the input “bookmobile”? “bookmobile” has its correspondent synset from WordNet, but still unfortunately, it is not within the 3500 synsets list we support, so no luck. Sounds a bit disappointed? But remember, these 3500 synsets have covered the most familiar objects we see in everyday life and we are just beginning!
The search engine works in an interactive way such that it will remind you if the synset you are searching for is not supported yet. We are working very hard to expand our supported synset pool hopefully our search engine can present more types of contents to the user.
The search engine can also handle the typo to some extent. If the user inputs “trruck”, where the duplicated “r” should be removed, the search engine will remind the user something like “The input query to media search engine contains error(s). Do you mean truck”, so the user can correct the input and resubmit the query.
To summarize, the input query must meet these requirements:
- 1. English only;
- 2. No typo;
- 3. A word or a sequence of words representing a noun, no adjective, no verb, and no adverb;
- 4. Be a synset in our 3500 supported synset list.
Search Engine
Our search engine is designed specifically to locate objects within videos. It works completely differently from other text-based or webpage-based search engine. As Fig.1 illustrates, the search engine firstly parses the user input string, then the string is converted into a list of synsets of WordNet. The search engine will go through the documents generated by the video understanding system, find out any record which has the same annotated label as the element of the target synset list. For example, if a 15 minutes video contains a shot of a “truck” from the 30th second to the 50th second time range, this video fragment will show up in the search result candidate list given the query submitted by the user is “truck”.
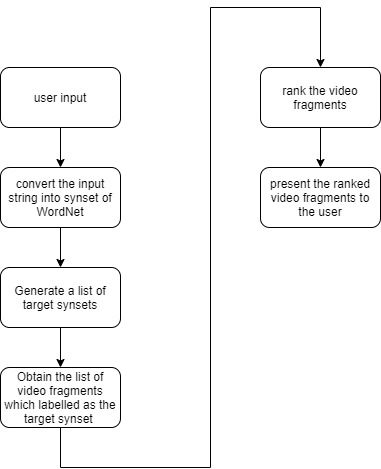
Fig.1 The workflow of the search engine
Rank the List of Videos
It’s very likely that the search engine generates a large list of video fragments labelled as “truck”, some of which may have a beautiful truck displayed in the foreground, but some may have a blurred truck in the background, or even some may not have a truck at all due to the false positive results. Thus, how to measure the correlation of the list of results to a perfect truck? We would like the video fragment with a large, clear, sharp truck in the center of frame, which is most preferable to humans, to appear at the top of the search result list. In order to achieve that, we need to rank these videos in terms of the correlation to a “truck”, such that we could present the most desirable result to the user at the top and trim the results which are less relevant or even erroneous.
We would like to invent a quantitative approach to measure the correlation of a particular video fragment to our target search object. Before going too far away, let’s intuitively talk about human visual system. Let’s still use our favorite example “truck”. When human watches a video with a truck appearing in it, the eyes can very efficiently locate the truck both temporarily and spatially. As a common sense, our visual system prefers a large truck, not a tiny one, to locate in the center of the frame. Also, we prefer a relative long video clip to represent the truck, not a short one (e.g., a 30 seconds clip is more preferable than a 1 second clip). Furthermore, we need the truck to stay in the video fragment from the beginning to the end, without gaps (e.g., a video clip with too many gaps without the truck in them is not preferred). These are all simple rules we learn from researches or even from our everyday experience. We plan to utilize them, measure them, then yield an expression to calculate the correlation of the video to our target object.
The design philosophy behind the ranking algorithm is simple: we would like to mimic the way how human visual system perceives objects and evaluate the observation results. Luckily, the video understanding system has located the target object from the videos for us, both temporarily and spatially. Also, we could obtain the saliency of the recognized object from the video understanding system. As illustrated in Fig. 2, the saliency of the truck in the left image is the highest, because the middle one is blurred and in the right one, the truck is in the background and partially covered by a worker.
Fig. 2 Three trucks (left: a perfect truck, middle: a blurred truck, right: a truck in the background)



Furthermore, the dimension, spatial location, time span and occurrence frequency all count into the observation result by the human visual system, so we need to consider them as well. Since the video understanding system has already indicated the position and area of the recognized object, thus we could easily obtain all the indicators above.
In summary, wearing the hat of mathematician, let’s yield the expression measuring the correlation of the video to a particular object. Given a video and a target object, assuming the average saliency of the recognized object from this video as s, the average area is a, the average occurrence frequency is d and the duration of the video fragments is t, so the correlation, denoted as c, is:
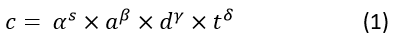
, where α, β, γ and δ are all experienced constants. Considering we are dealing with video from the internet, we could somehow parse the metadata of the video and get the video creation date for example, and people prefer to watch more recent video than the older one, thus we could naturally add the date time factor into the ranking result. Assume the video is created n years later from Jan 1, 1970 epoch time, so expression (1) can be modified as:
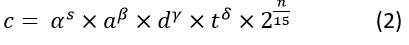
, where 2^(n/15) means every 15 years later, the correlation will double, thus the more recent video is more likely to appear at the top of the result list.
The search engine will calculate the correlation value for each video in the result video list, then rank them, put the video with the highest correlation value at the top and present to the user. We hope the videos with the best visually appealing target object to be showed at the top of the result list to maximize the user experience.
UI Design
It may be worthwhile to talk about the UI design to better assist the audience to use our search engine. The UI looks like very similar with the main stream search engines over the market. The main page of the search engine is just a text box where the user can input the query string, and a “go!” button underneath to kick off the search. We place the links to our resources (self-introduction, user guide, technical description, and etc.) in the footer of the webpage. We somewhat follow the design philosophy of minimalism such that nothing unrelated to video search will appear in our webpage. We try the best to let our users focus on the video content they are searching for but won’t place any distracting content on our webpage.
Other Topics
The video search engine is the first product we unveil to the public. We target it as an interface to our video understanding system. The video understanding system crawls videos from the internet continuously, generates documents describing the video contents, then the search engine provides an entry to access the document cluster.
The evaluation of the search results can be categorized as three acceptance levels as Table 1 shows:
| Acceptance levels | Explanation |
|---|---|
| Correct (level 1) | The search result is exactly what the user is searching for. |
| Relevant (level 2) | The search result is not exactly what the user is searching for, but relevant. |
| Wrong (level 3) | The search result is not what the user is searching for with zero relevance. |
Still using the example of “truck”, if the search result is a “Ford F150 pickup”, it’s a level 1 result. If it’s a “Winnebago class C motorhome”, we think it belongs to level 2 category because a motorhome sometimes visually looks like a truck but not a truck. If it’s a sedan like “Honda Civic”, it’s in level 3 category because it’s un-relevant either visually or conceptually to a truck. Obviously, we would like our search results to drop in the zone of level 1 as much as possible. Based on our experience, the ranking algorithm can efficiently rank the videos in consistence with the acceptance levels. However, in some cases, the search results are not satisfactory in two ways: 1) the percentage of level 1 result is too small (too much level 2 or 3 results); 2) There is no level 1 result at all.
To mitigate or address these issues, there are two approaches: 1) Improve the object recognition AI model such that the model can recognize more objects and distinguish similar objects better. For example, a better AI model should distinguish motorhome with truck better. 2) Crawls as much video as possible. The larger the video pool is, the larger number of objects the video understanding system can watch, thus more real truck will enter the search result candidate list such that we will get more level 1 results and place them at the top of the result list. The rule is simple here: the more we watch, the better result we get.
The End
We hope our product to serve as a novel human-computer interface, where the computer mimics our visual neural system and our brain cognition system. The computer is not only a machine just generating binary bit stream, or a network node transferring data, or a computing unit undertaking pre-defined computation tasks, but also a cognition entity, which can observe, make notes, or even somewhat understand our natural world in the similar way as ourselves. Our search engine is such a tool bridging between the human user and the computer, opening a door to a brand new world and we could ask the computer “what do you see?”.
Reference
[1] "Princeston University "About WordNet."," 2010. [Online]. Available: https://wordnet.princeton.edu/.